
In my latest tutorial I walked readers through a Python script designed to download tweets by a set of Twitter users and insert them into an SQLite database. In this post I will provide my own thoughts on the pros and cons of using a relational database such as SQLite vs. a “noSQL” database such as MongoDB. These are my two go-to databases for downloading and managing Big Data and there are definite advantages and disadvantages to each.
The caveat is that this discussion is for researchers. Businesses will almost definitely not want to use SQLite for anything but simple applications.
The Pros and Cons of SQLite
SQLite has a lot going for it. I much prefer SQLite over, say, SQL. SQLite is the easiest of all relational databases. Accordingly, for someone gathering data for research SQLite is a great option.
For one thing, it is pre-installed when you install Anaconda Python (my recommended installation). There’s none of typical set-up with a MySQL installation, either — steps such as setting up users and passwords, etc. With Anaconda Python you’re good to go.
Moreover, SQLite is portable. Everything is contained in a single file that can be moved around your own computer or shared with others. There’s nothing complicated about it. Your SQLite database is just a regular file. Not so with MySQL, for instance, which would need to be installed separately, have user permissions set up, etc., and is definitely not so readily portable.
So, what’s the downside? Two things. One, there is the set-up. To get the most out of your SQLite database, you need to pre-define every column (variable) you’re going to use in the database. Every tweet, for instance, will need to have the exact same variables or else your code will break. For an example of this see my recent tutorial on downloading tweets into an SQLite database.
The other shortcoming flows from the pre-defining process. Some social media platforms, such as Twitter, have relatively stable APIs, which means you access the same variables the same way year in and year out. Other platforms, though (that’s you, Facebook), seem to change their API constantly, which means your code to insert Facebook posts into your SQLite database will also constantly break.
Here’s a screenshot of what your SQLite database might look like:
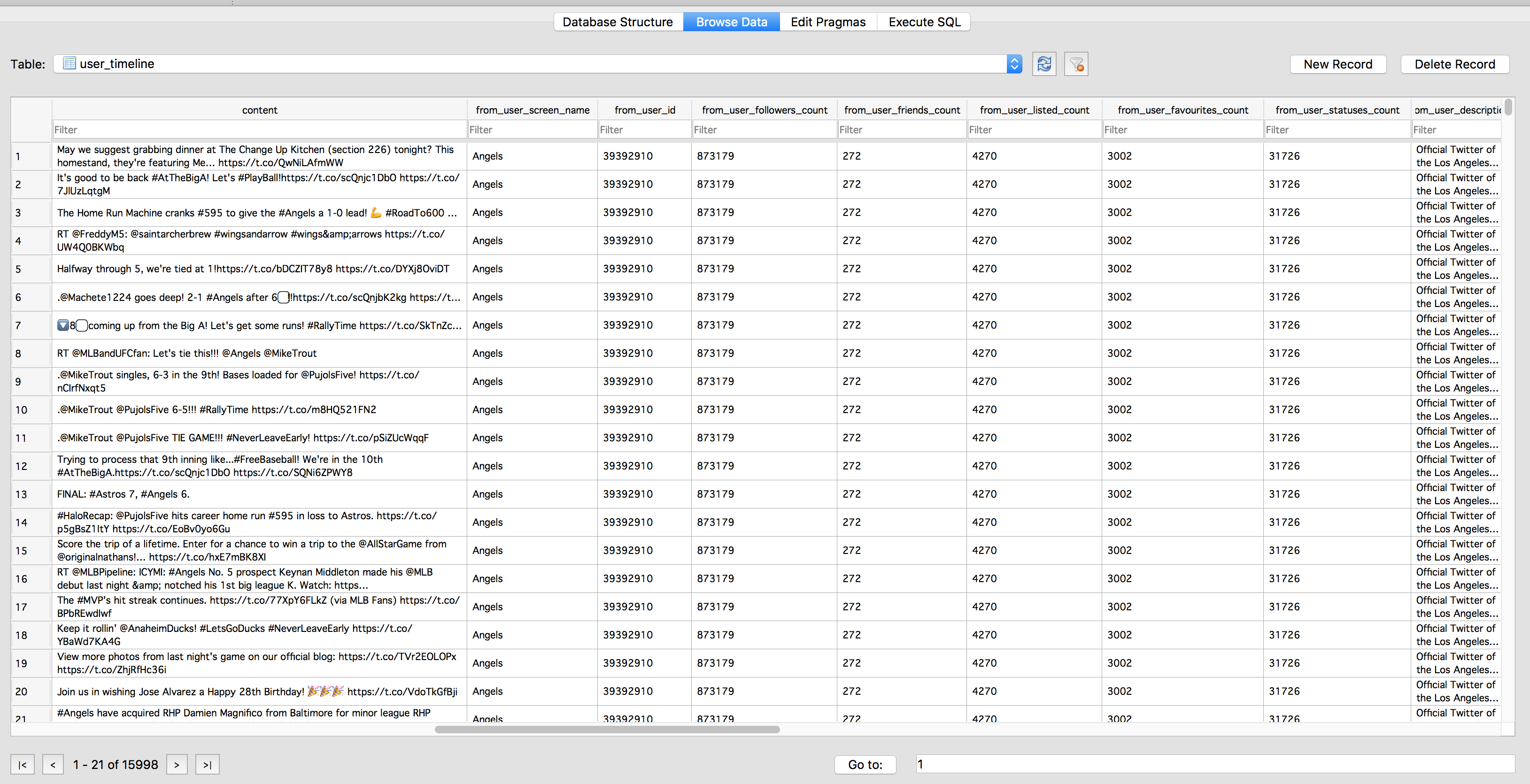
As you can see, it’s set up like a typical flat database like an Excel spreadsheet or PANDAS or R dataframe. The columns are all pre-defined.
The Pros and Cons of MongoDB
The SQLite approach contrasts starkly with the “noSQL” approach represented by MongoDB. A primary benefit is that MongoDB is tailor-made for inserting the types of data returned by a social media platform’s API — particularly JSON.
For instance, the Twitter API returns a JSON object for each tweet. In a prior tutorial I provide an overview of this. The code block below shows the first five lines of JSON (one line per variable) for a typical tweet object returned by the Twitter API:
“_id” : ObjectId(“595a71173ffc5a01d8f27de7”),
“contributors” : null,
“quoted_status_id” : NumberLong(880805966375202816),
“text” : “RT @FL_Bar_Found: Thank you for your support, Stephanie! https://t.co/2vxXe3VnTU”,
“time_date_inserted” : “12:30:15_03/07/2017”,
….
}
And to see the full 416 lines of JSON code for a single tweet object click on expand source below:
[code] {"_id" : ObjectId("595a71173ffc5a01d8f27de7"),
"contributors" : null,
"quoted_status_id" : NumberLong(880805966375202816),
"text" : "RT @FL_Bar_Found: Thank you for your support, Stephanie! https://t.co/2vxXe3VnTU",
"time_date_inserted" : "12:30:15_03/07/2017",
"query_screen_name" : "@FL_Bar_Found",
"is_quote_status" : true,
"in_reply_to_status_id" : null,
"id" : NumberLong(881145993059864580),
"favorite_count" : 0,
"source" : "<a href=\"http://twitter.com/download/iphone\" rel=\"nofollow\">Twitter for iPhone</a>",
"truncated" : false,
"retweeted" : false,
"coordinates" : null,
"entities" : {
"symbols" : [],
"user_mentions" : [
{
"indices" : [
3,
16
],
"screen_name" : "FL_Bar_Found",
"id" : NumberLong(2680494548),
"name" : "FloridaBarFoundation",
"id_str" : "2680494548"
}
],
"hashtags" : [],
"urls" : [
{
"url" : "https://t.co/2vxXe3VnTU",
"indices" : [
57,
80
],
"expanded_url" : "https://twitter.com/theflabar/status/880805966375202816",
"display_url" : "twitter.com/theflabar/stat…"
}
] },
"date_inserted" : "03/07/2017",
"in_reply_to_screen_name" : null,
"in_reply_to_user_id" : null,
"retweet_count" : 2,
"id_str" : "881145993059864580",
"favorited" : false,
"retweeted_status" : {
"contributors" : null,
"truncated" : false,
"text" : "Thank you for your support, Stephanie! https://t.co/2vxXe3VnTU",
"is_quote_status" : true,
"in_reply_to_status_id" : null,
"id" : NumberLong(880957463801057281),
"favorite_count" : 5,
"source" : "<a href=\"http://twitter.com/download/iphone\" rel=\"nofollow\">Twitter for iPhone</a>",
"quoted_status_id" : NumberLong(880805966375202816),
"retweeted" : false,
"coordinates" : null,
"quoted_status" : {
"contributors" : null,
"truncated" : true,
"text" : "New @FlaBarYLD #ProBono Chair Stephanie Cagnet Myron @CagnetMyronLaw has only been at work 1 week – but she’s busy!… https://t.co/nASTbHyuzW",
"is_quote_status" : false,
"in_reply_to_status_id" : null,
"id" : NumberLong(880805966375202816),
"favorite_count" : 12,
"source" : "<a href=\"http://twitter.com\" rel=\"nofollow\">Twitter Web Client</a>",
"retweeted" : false,
"coordinates" : null,
"entities" : {
"symbols" : [],
"user_mentions" : [
{
"indices" : [
4,
14
],
"screen_name" : "FlaBarYLD",
"id" : 460499634,
"name" : "Florida Bar YLD",
"id_str" : "460499634"
},
{
"indices" : [
53,
68
],
"screen_name" : "CagnetMyronLaw",
"id" : NumberLong(4850153337),
"name" : "Cagnet Myron Law, PA",
"id_str" : "4850153337"
}
],
"hashtags" : [
{
"indices" : [
15,
23
],
"text" : "ProBono"
}
],
"urls" : [
{
"url" : "https://t.co/nASTbHyuzW",
"indices" : [
117,
140
],
"expanded_url" : "https://twitter.com/i/web/status/880805966375202816",
"display_url" : "twitter.com/i/web/status/8…"
}
] },
"in_reply_to_screen_name" : null,
"id_str" : "880805966375202816",
"retweet_count" : 2,
"in_reply_to_user_id" : null,
"favorited" : false,
"user" : {
"follow_request_sent" : null,
"has_extended_profile" : false,
"profile_use_background_image" : true,
"time_zone" : "Pacific Time (US & Canada)",
"id" : 1024389338,
"default_profile" : true,
"verified" : true,
"profile_text_color" : "333333",
"profile_image_url_https" : "https://pbs.twimg.com/profile_images/489757746669944832/qL0j6UB1_normal.jpeg",
"profile_sidebar_fill_color" : "DDEEF6",
"is_translator" : false,
"geo_enabled" : true,
"entities" : {
"url" : {
"urls" : [
{
"url" : "http://t.co/h6TDPEl3jy",
"indices" : [
0,
22
],
"expanded_url" : "http://www.FloridaBar.org",
"display_url" : "FloridaBar.org"
}
] },
"description" : {
"urls" : [] }
},
"followers_count" : 10418,
"protected" : false,
"id_str" : "1024389338",
"default_profile_image" : false,
"listed_count" : 498,
"lang" : "en",
"utc_offset" : -25200,
"statuses_count" : 75802,
"description" : "Statewide professional organization of lawyers that serves as an advocate & intermediary for attorneys, the court & the public. Retweets are not endorsements.",
"friends_count" : 2001,
"profile_link_color" : "1DA1F2",
"profile_image_url" : "http://pbs.twimg.com/profile_images/489757746669944832/qL0j6UB1_normal.jpeg",
"notifications" : null,
"profile_background_image_url_https" : "https://abs.twimg.com/images/themes/theme1/bg.png",
"profile_background_color" : "C0DEED",
"profile_banner_url" : "https://pbs.twimg.com/profile_banners/1024389338/1377117432",
"profile_background_image_url" : "http://abs.twimg.com/images/themes/theme1/bg.png",
"name" : "The Florida Bar",
"is_translation_enabled" : false,
"profile_background_tile" : false,
"favourites_count" : 54326,
"screen_name" : "theflabar",
"url" : "http://t.co/h6TDPEl3jy",
"created_at" : "Thu Dec 20 14:46:06 +0000 2012",
"contributors_enabled" : false,
"location" : "Tallahassee, Florida",
"profile_sidebar_border_color" : "C0DEED",
"translator_type" : "none",
"following" : null
},
"geo" : null,
"in_reply_to_user_id_str" : null,
"possibly_sensitive" : false,
"lang" : "en",
"created_at" : "Fri Jun 30 15:11:21 +0000 2017",
"in_reply_to_status_id_str" : null,
"place" : null,
"metadata" : {
"iso_language_code" : "en",
"result_type" : "recent"
}
},
"entities" : {
"symbols" : [],
"user_mentions" : [],
"hashtags" : [],
"urls" : [
{
"url" : "https://t.co/2vxXe3VnTU",
"indices" : [
39,
62
],
"expanded_url" : "https://twitter.com/theflabar/status/880805966375202816",
"display_url" : "twitter.com/theflabar/stat…"
}
] },
"in_reply_to_screen_name" : null,
"id_str" : "880957463801057281",
"retweet_count" : 2,
"in_reply_to_user_id" : null,
"favorited" : false,
"user" : {
"follow_request_sent" : null,
"has_extended_profile" : false,
"profile_use_background_image" : false,
"time_zone" : "Eastern Time (US & Canada)",
"id" : NumberLong(2680494548),
"default_profile" : false,
"verified" : false,
"profile_text_color" : "000000",
"profile_image_url_https" : "https://pbs.twimg.com/profile_images/821370669573275649/SOQ1xHS3_normal.jpg",
"profile_sidebar_fill_color" : "000000",
"is_translator" : false,
"geo_enabled" : true,
"entities" : {
"url" : {
"urls" : [
{
"url" : "http://t.co/pTHhl5lG9P",
"indices" : [
0,
22
],
"expanded_url" : "http://www.thefloridabarfoundation.org",
"display_url" : "thefloridabarfoundation.org"
}
] },
"description" : {
"urls" : [
{
"url" : "http://t.co/65UE4Zk0tC",
"indices" : [
94,
116
],
"expanded_url" : "http://bit.ly/13JbjCY",
"display_url" : "bit.ly/13JbjCY"
}
] }
},
"followers_count" : 1533,
"protected" : false,
"id_str" : "2680494548",
"default_profile_image" : false,
"listed_count" : 41,
"lang" : "en",
"utc_offset" : -14400,
"statuses_count" : 2012,
"description" : "The mission of The Florida Bar Foundation is to provide greater access to justice in Florida. http://t.co/65UE4Zk0tC",
"friends_count" : 532,
"profile_link_color" : "0084B4",
"profile_image_url" : "http://pbs.twimg.com/profile_images/821370669573275649/SOQ1xHS3_normal.jpg",
"notifications" : null,
"profile_background_image_url_https" : "https://abs.twimg.com/images/themes/theme1/bg.png",
"profile_background_color" : "000000",
"profile_banner_url" : "https://pbs.twimg.com/profile_banners/2680494548/1484665070",
"profile_background_image_url" : "http://abs.twimg.com/images/themes/theme1/bg.png",
"name" : "FloridaBarFoundation",
"is_translation_enabled" : false,
"profile_background_tile" : false,
"favourites_count" : 2002,
"screen_name" : "FL_Bar_Found",
"url" : "http://t.co/pTHhl5lG9P",
"created_at" : "Fri Jul 25 21:17:50 +0000 2014",
"contributors_enabled" : false,
"location" : "Florida",
"profile_sidebar_border_color" : "000000",
"translator_type" : "none",
"following" : null
},
"geo" : null,
"in_reply_to_user_id_str" : null,
"possibly_sensitive" : false,
"lang" : "en",
"created_at" : "Sat Jul 01 01:13:21 +0000 2017",
"quoted_status_id_str" : "880805966375202816",
"in_reply_to_status_id_str" : null,
"place" : {
"country_code" : "US",
"url" : "https://api.twitter.com/1.1/geo/id/00d511d335cd9fb6.json",
"country" : "United States",
"place_type" : "city",
"bounding_box" : {
"type" : "Polygon",
"coordinates" : [
[
[
-81.2445014,
28.489488
],
[
-81.1256316,
28.489488
],
[
-81.1256316,
28.568794
],
[
-81.2445014,
28.568794
] ] ] },
"contained_within" : [],
"full_name" : "Alafaya, FL",
"attributes" : {},
"id" : "00d511d335cd9fb6",
"name" : "Alafaya"
},
"metadata" : {
"iso_language_code" : "en",
"result_type" : "recent"
}
},
"user" : {
"follow_request_sent" : null,
"has_extended_profile" : false,
"profile_use_background_image" : true,
"time_zone" : "Eastern Time (US & Canada)",
"id" : 493169878,
"default_profile" : false,
"verified" : false,
"profile_text_color" : "333333",
"profile_image_url_https" : "https://pbs.twimg.com/profile_images/872490334655270916/jxMbCTKe_normal.jpg",
"profile_sidebar_fill_color" : "F3F3F3",
"is_translator" : false,
"geo_enabled" : true,
"entities" : {
"url" : {
"urls" : [
{
"url" : "https://t.co/6sIP0DbThb",
"indices" : [
0,
23
],
"expanded_url" : "http://www.legalaidocba.org",
"display_url" : "legalaidocba.org"
}
] },
"description" : {
"urls" : [
{
"url" : "https://t.co/8HiQPlRDyv",
"indices" : [
133,
156
],
"expanded_url" : "https://vimeo.com/190166320",
"display_url" : "vimeo.com/190166320"
}
] }
},
"followers_count" : 447,
"protected" : false,
"id_str" : "493169878",
"default_profile_image" : false,
"listed_count" : 5,
"lang" : "en",
"utc_offset" : -14400,
"statuses_count" : 3362,
"description" : "Development, fundraiser, communications, photographer. Breakfast of Champions boc@legalaidocba.org Retweets do not imply endorsement https://t.co/8HiQPlRDyv",
"friends_count" : 2161,
"profile_link_color" : "990000",
"profile_image_url" : "http://pbs.twimg.com/profile_images/872490334655270916/jxMbCTKe_normal.jpg",
"notifications" : null,
"profile_background_image_url_https" : "https://abs.twimg.com/images/themes/theme7/bg.gif",
"profile_background_color" : "EBEBEB",
"profile_banner_url" : "https://pbs.twimg.com/profile_banners/493169878/1496917809",
"profile_background_image_url" : "http://abs.twimg.com/images/themes/theme7/bg.gif",
"name" : "Donna Haynes",
"is_translation_enabled" : false,
"profile_background_tile" : false,
"favourites_count" : 1997,
"screen_name" : "lasocba",
"url" : "https://t.co/6sIP0DbThb",
"created_at" : "Wed Feb 15 14:26:11 +0000 2012",
"contributors_enabled" : false,
"location" : "Orlando, Florida",
"profile_sidebar_border_color" : "DFDFDF",
"translator_type" : "none",
"following" : null
},
"geo" : null,
"in_reply_to_user_id_str" : null,
"possibly_sensitive" : false,
"lang" : "en",
"created_at" : "Sat Jul 01 13:42:30 +0000 2017",
"quoted_status_id_str" : "880805966375202816",
"in_reply_to_status_id_str" : null,
"place" : null,
"metadata" : {
"iso_language_code" : "en",
"result_type" : "recent"
}
}
[/code]
Here is where MongoDB excels. All we need to do is grab the tweet object and tell MongoDB to insert it into our database. Do you have different columns in each tweet? MongoDB doesn’t care — it will just take whatever JSON you throw at it and insert it into your database. So if you are working with JSON objects that have different variables or different numbers of columns — or if Facebook changes its API again — you will not need to update your code and your script will not break because of it.
Here’s a screenshot of what the first 40 objects (tweets) in your MongoDB database might look like. You can see that the number of fields (variables) is not the same for each tweet — some have 29, some have 30, or 31, or 32:

And here’s what the first tweet looks like after expanding the first object:

As you can see, it looks like the JSON object returned by the Twitter API.
In effect, MongoDB is great in situations where you would like to quickly grab all the data available and quickly throw it into a database. The downside of this approach is that you will have to do the defining of your data later — before you can analyze it. I find this to be less and less problematic, however, since PANDAS has come around. I would much rather extract my data from MongoDB (one line of code) and do my data and variable manipulations in PANDAS rather than mess around with SQLAlchemy before even downloading the data into an SQLite database.
A final benefit of MongoDB is its scalability. You have 10 million tweets to download? What about 100 million? No issues with MongoDB. With SQLite, in contrast, let’s say 1 million tweets would be a good upper limit before performance drags considerably.
MongoDB does have its downsides, though. Much like MySQL, MongoDB needs to be “running” before you insert data into it. If your server is running 24/7 that is no issue. Otherwise you’ll have to remember to restart your MongoDB server each time you want to either insert data into your database or extract data you’ve already inserted. MongoDB also has higher “start-up” costs; it is not as easy to install as SQLite and you may or may not run into disk permissions issues, username and password issues, etc. Cross your fingers and will only take you half an hour — once — and then you’re good to go from then on.
Finally, a MongoDB database is not a “file” like an SQLite database. This makes moving or sharing your database more troublesome. Not terribly onerous but a few extra steps. Again, if you are importing your MongoDB database into PANDAS and then using PANDAS for your data manipulations, etc., then this should not be an issue. You can easily share or move your PANDAS databases or export to CSV or Excel.
Summary
Here is a summary of the pros and cons of SQLite and MongoDB for use as a Big Data-downloading database.
| SQLite | MongoDB | |
|---|---|---|
| Portability | Easy to share/move an SQLite database. | Considerably more complicated. May not be an issue for you if you're work process is to export your data into PANDAS. |
| Ease of use | SQLite is simple. The database is just a single file that does not need to be 'running' 24/7. | More complicated than SQLite. The MongoDB server needs to be running before your Python script can insert the data. |
| Ease of Setup | Very easy. If you have installed Anaconda Python you are good to go. | Considerably more complicated set-up. But it is a one-time process. If you are lucky or are comfortable with the Terminal this one-time set-up process should not take more than an hour. |
| Scalability | Beyond a certain limit your SQLite database will become unwieldy. I've have up to a million tweets without too much difficulty, however. | Can be as small or as big as you'd like. |
| Setting up code to insert tweets | Needs to be detailed. Every column needs to be defined in your code and accounted for in each tweet. | Easy. MongoDB will take whatever JSON Twitter throws at it and insert it into the database. |
| Robustness to API Changes | Not robust. The Facebook API, for instance, changes almost constantly. Your database code will have to be updated each time or it will break when it tries to insert into SQLite. | Extremely robust. Easy. MongoDB will take whatever JSON you throw at it and insert it into the database. |
If you’ve found this post helpful please share on your favorite social media site.
I my next post I will provide a tutorial of how to download tweets into a MongoDB database. Until then, happy coding!
