…
Continue Reading about Chapter 3 – Analyzing Twitter Data by Time Period
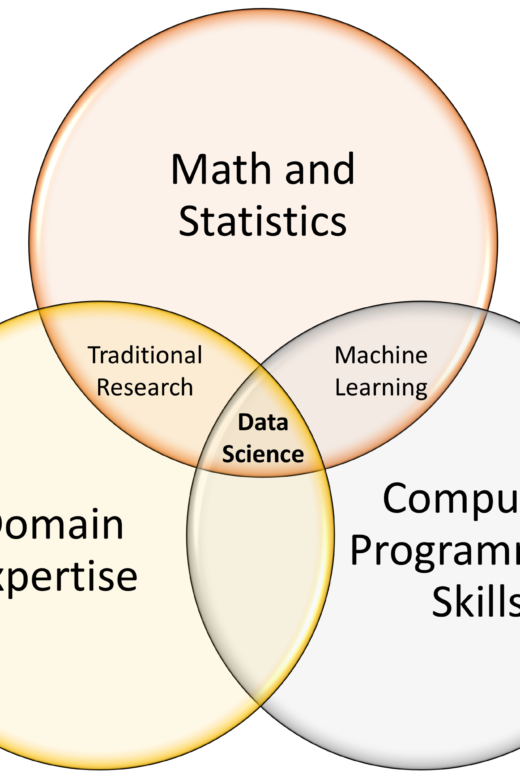
Social Media, Organizations, and Academic Research
One of the buzz-words in business schools is data analytics or, in an accounting school, accounting analytics. But what exactly is …